
What are web crawlers?
A web crawler, also known as a bot, is what search engines use to ‘read’ a website so that it can index it in the search results.
What is the role of web crawlers?
These automated systems download and index the content of a website, so that it can understand what information is on it and present it to users when it’s relevant.
How do web crawlers work?
A web crawler works by discovering URLs, reading them, and categorising the web pages they lead to. In the process, it discovers linked URLs, so it makes a note to crawl those next – this is why the structure of your site and the way you link internally is so important!
What is website crawlability?
Website crawlability refers to the ease with which a web crawler can ‘crawl’ your website’s content. This is different to indexability, which refers to the ease with which the content can be indexed.
How can you check to see if your website is crawlable and indexable?
A site audit is your first port of call in discovering your website’s crawlability and indexability, and should ideally be carried out by a technical SEO specialist. Platforms such as Ahrefs have crawlability and indexability tools that can help you understand how easy it is for search engine crawlers to download and index your content.
What are crawlability problems?
Crawlability problems are ones that stop Google from being able to crawl your site; they’re essentially access problems, and ones that can cost you dearly in the SERPs.
How do crawlability issues affect SEO?
If you’ve got crawlability issues on your site, it means that Google crawlers can’t access some or all of your web pages, which means they’re invisible on the results pages. Google can’t index the pages, so it can’t rank them, either. Therefore, you’ll be losing so much precious organic traffic by failing to address crawlability issues on your site.
How to check crawl errors
The first step to fixing these problems is to find out about them in the first place. Whilst there are plenty of tools out there that will help you find crawl errors, the best and most straightforward place to start is Google Search Console. It divides crawl errors into site errors, which are urgent because they affect the entire site, and URL errors, which are still a priority to fix, but only affect individual pages.
We’d suggest keeping a regular eye on your crawl errors, so that you can fix them quickly and stand the best chance of being indexed and displayed in the SERPs.
TOP 16 crawlability problems and how to fix them
Pages blocked in robots.txt file
A robots.txt file tells a crawler what it should and shouldn’t look at on a website – if that file contains the following, you’re blocking crawlers from your entire website:
User-agent: *
Disallow: /
The good news is that all you need to do here is change ‘disallow’ to ‘allow’. If there are sections of your website referred to after the ‘/’ following ‘disallow’, such as your products, these are blocked from Google, so ‘allow’ those if you’d like them to be indexed.
Nofollow links
You can tell search engines not to crawl the URLs that a page links to by attaching a ‘nofollow’ tag in the HTML. This means that any internal links on the page won’t be crawled by Google if the tag is present. Check that any nofollow tags on your website are supposed to be there, and remove them if they’re not.
You can check for nofollow links right from your browser: just right click and ‘view page source’. Look for links in the page’s HTML, and if you see rel=’nofollow’, you’ll know that a no follow tag applied to the page.
Poor site architecture
How your pages are organised across your website has a bearing on how the entire site is crawled, and poor site architecture can hamper the process. Every page on the site should be just a few ‘clicks’ away from the home page, with internal links pointing to every page. Pages without internal links directed to them are called ‘orphan’ web pages, and you don’t want any of those if you want it to rank.
In order to ensure good site architecture, take a birds eye view of your site, and organise the pages logically, in a family-tree style structure.
A lack of internal links
The above is a good example of why internal links are important, so it makes sense that a lack of them can create crawlability problems. Orphan pages won’t get crawled, so ensure that each page on your site has relevant pages linking to it.
A bad sitemap
A site map uploaded to the root directory of your site (you can do this via Google Search Console) shows search engines what pages should be crawled, so excluding a page from this map means that it won’t be crawled. Check in with your sitemap to ensure it’s not missing any pages that you want to rank!
‘Noindex’ tags
You can indicate to search engine crawlers that you don’t want a page to be indexed, and you can do this by attaching a ‘noindex’ meta robots tag, that looks like this: <meta name=”robots” content=”noindex”>. If you leave this tag on the page for a long time, the links on it will gradually stop being crawled, creating crawlability issues long term for your site.
You can find pages on your site that are blocked from being crawled by a noindex tag by filtering your pages by ‘Excluded by noindex tag’ in Google Search Console. From here, you can review and control which pages are blocked from crawlers, and remove the tags if necessary.
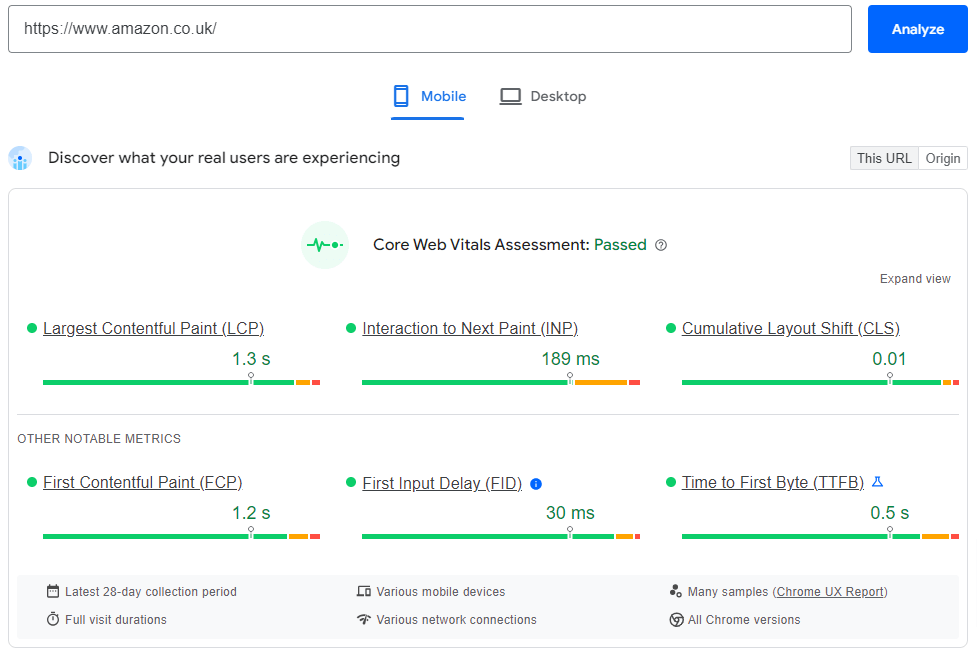
Poor site speed
Poor site speed isn’t just a major frustration to your users, it can affect Google itself crawling your pages. Despite being automated, crawlers have limited time with which to crawl your site, so a site that loads slowly takes up precious ‘crawl session’ time, meaning that less of your pages will get crawled. Not good news for your rankings!
Site speed is one of your Core Web Vitals – keeping on top of these goes some way to making your website easily crawlable.
Broken internal links (404 errors)
Ever clicked on a link and it leads nowhere? This is a 404 error, where a link within a website is essentially ‘broken’. This is an obvious crawlability error, as it prevents a web crawler from getting around your site.
Google Search Console has 404-finding capabilities, so ensure you check regularly for the occurrence of these errors, substituting broken links for new ones or implementing 301 redirects to preserve the crawlability and general navigation of your site.
Server side errors (5XX codes)
Servers being unable to fulfil requests when search engines attempt a website crawl can affect your site being downloaded and indexed. This is an issue to head to your web developer with, who will be able to help configure the server correctly to prevent these issues.
Redirect loops
When one web page redirects to another, which then redirects to the original page, it’s known as a redirect loop – and web crawlers don’t like them. Redirects should be used to direct users clicking on one URL to another, relevant URL, so to fix this problem, ensure redirects all point to a final destination page.
Pages with restricted access
Access restrictions such as password protection or login functionality can halt a crawler in its tracks. Whilst it often makes sense to have members only areas, or password protected access for content that isn’t for everyone, there shouldn’t be anything behind these restrictions that you want crawled.

URL parameters
Known also as query strings, URL parameters are best demonstrated by ecommerce pages, where a seemingly infinite number of URL variations could be available after a question mark once filters are applied. For example, example.com/skirts?colour=green.
Not every variation is likely to be used by users, so it’s well worth going through your URL parameters and preventing the crawling of any that aren’t likely to be helpful, to ensure crawlers aren’t wasting their time (otherwise known as ‘crawl budget’). You can do this by using your robots.txt file, or implementing nofollow tags for links to the URLs within those parameters.
Javascript blocked in robots.txt file
Your robots.txt file could be blocking Javascript on your site, which could lead to major crawlability issues if big swathes of your page relies on Javascript. There’s a section within Google Search Console named ‘blocked resources’, under which you can identify any Javascript that your robots.txt file is blocking before working with your developer to unblock anything vital.
Duplicate content
Content that is the same or almost the same appearing in different areas of your site can prove troublesome to a search engine crawler. Of course, some content is likely to crop up repeatedly across a site on purpose, but a good example of when it shouldn’t is a blog post that’s available via multiple different URLs. Google Search Console handily lets you consolidate content like this under canonical tags, helping direct the crawler to its destination more quickly.
Poor mobile experience
So much browsing is done on mobile devices these days, so a poor mobile experience is a huge turn off not only for the user, but search engines too. In fact, Google uses mobile-first indexing thanks to the information gathered by its crawlers, so you’re doing your site a huge disservice if you don’t prioritise the mobile experience.
Manually review your site on mobile devices so that you can rectify any responsiveness problems with your developer, and keep an eye on your site speed, too.
Dynamically-inserted links
Links within dynamic content such as Javascript can be tricky for a search engine crawler to follow and understand, so these are best avoided for pages you want to be easily crawled, downloaded, indexed and, ultimately, ranked.
How to stay ahead of website crawlability issues
Crawlability is something to keep on top of as part of your SEO-hygiene, as fixing issues today won’t mean that more won’t occur down the line. Therefore, making the following two tasks part of your monthly site routine will help you stay ahead of website crawl errors:
Frequent website audits
Many online tools, such as SEMrush, offer website audit tools, which can quickly sweep your site and flag up anything that could be a snagging point for website crawlers. Making these kinds of audits a regular occurrence can help you keep on top of anything that may have cropped up.
Check Google Search Console
To check your website crawlability, Google Search Console is your friend, with reports available within it that identify crawl errors produced by any of the issues we’ve mentioned within each article. You’ll then know what the error is, what pages it’s affecting, and how you need to fix it.
Need help with your website’s crawlability?
We understand that website crawlability is on the technical end of the SEO scale, and not only is there a lot to check and potentially rectify, but there’s a lot to get your head around too. Experts like the 427 team are best placed to handle all of this for you, armed with the knowledge to identify website crawl issues and put them right to give your site the best chance of being discovered.
For full-package SEO management, including technical support from our technical SEO specialists, get in touch with us today.



